

안녕하세요, 에디터 SA입니다. AI 개발과 학습에 있어 꼭 필요한 것이 있습니다. 바로 ‘GPU’인데요. 이 GPU에 대해서, 소신 발언을 해볼까 합니다. GPU는… 비쌉니다.🤑 모두 알고 계시고, 공감하실 이야기일 거예요. GPU 중 특히 AI 개발에 필요한 고사양의 GPU는 더욱 비싸고, 요새는 구하기도 어렵습니다. 혹시 담당하는 프로젝트가 AI 개발에 관련된 것이라면, 제일 먼저 부딪히게 될 문제가 바로 이 ‘GPU’일 가능성이 높습니다.
GPU를 어찌저찌 구하는 데 성공했다면? 다음 문제가 기다리고 있습니다. 데이터센터를 구축하기 위해 A100과 밴드 같은 적절한 하드웨어를 마련했다고 가정해 보겠습니다. 일단 개발하고 있는 AI 모델이 하나이면, GPU 하나에 AI 모델 하나를 할당하는 단순한 계산법으로 분배가 되겠지요. 그러나 이 AI 모델이 LLM이나 LMM이어서 GPU 하나로 개발과 학습을 감당할 수가 없다면? 2개를 할당해야 할 거예요. 혹은 3개, 4~5개를 사용해 더 빠른 학습을 도모할 수도 있을 거고요.🤔

그럼, 효율을 높이기 위해 A라는 모델의 개발 및 학습에 GPU 5장을 사용한다고 해보겠습니다. 그런데 옆 부서에서 새로운 AI 모델을 개발하기 시작합니다. 그 옆옆 부서도, 옆옆옆 부서도요. 새로 모델을 개발하기 시작한 부서들은 GPU 확보에 혈안이 되었습니다. 그러다 그들의 시선이, 여러분의 AI 모델이 사용 중인 GPU 5장에 닿습니다. “쟤네는 저 귀한 걸 5장이나 써?😤”
상황이 난처해졌습니다.🥲 사실, 여러분의 AI 모델에 GPU를 3.1장만 활용해도 학습 효율에 지장이 없습니다. 그런데, 이 ‘0.1장’이라는 애매한 용량 때문에 4장을, 그리고 ‘혹시 몰라’ 병에 홀려 5장까지 점유하게 된 것이죠. 여러 부서장의 거듭한 회의 결과, 여러분은 적어도 다른 부서에 GPU 한 장씩 할당해 주어야 하게 되었습니다. 다른 부서들이 필요로 하는 GPU의 용량을 환산하면 0.8장, 0.7장 정도이며 1장이 채 안 됩니다. 그러나 두 부서에서 GPU 1장씩, 총 2장을 가져갔어요. 그럼, 여러분에게 남은 GPU는 3장입니다. 이제, ‘0.1장’이라고 하는 수치가 아쉽기 시작합니다.🤦
그렇다고 1장을 다시 되가져 오기는 애매합니다. 막상 AI 모델 학습을 위해 데이터센터를 가동해 보니, 그리 크지 않은 규모인데도 전력 소모가 엄청났던 것이죠. 사실 5장을 사용하면서 눈치도 조금 보였더랬습니다. 엄청난 전기세, 데이터센터 쿨링을 위한 각종 유지 비용 등을 알게 되면서, GPU를 5장 쓰고 있는 게 어쩐지 눈치 보이게 된 것이죠.🥲 (사내 데이터센터에 있는 GPU는 총 10장, 아주 귀여운 수준이었고요) GPU를 5장 사용하는 동안에는 그 비용의 책임이 모두 여러분의 부서에 있는 것만 같았던 지라, 다시 되가져올 엄두가 조금… 나지 않습니다.🤦
이런 상황에서 해결책이 될 수 있는 것, 바로 MIG입니다.
[ MIG가 뭔지 좀 더 알려 주세요! ]

MIG는 Multi-Instance GPU의 약자로, GPU를 독립적인 인스턴스로 분할하는 것입니다. 엔비디아 암페어(Ampere) 아키텍처에 적용되어 있는데, 이 아키텍쳐의 개념을 잘 모르신다면, 엔비디아의 GPU 중 A100을 떠올리시면 됩니다.
MIG로 A100을 분할하면, 각 인스턴스는 고유한 메모리, 캐시, 스트리밍 멀티프로세서를 사용해 동시에 실행할 수 있게 됩니다. 일종의 파티션을 세워 GPU를 나눈다고 생각하시는 편이 좀 더 머리에 연상이 잘 되실 거예요. 최대 7개까지 만들 수 있습니다. 그 말인즉슨, 1개의 GPU를 7개처럼 사용할 수 있다는 의미이므로, 활용도 역시 7배가 늘어나게 됩니다.😮
AI 추론 작업의 경우 최신 GPU가 제공하는 성능을 모두 활용하지는 않기 때문에, MIG 모드를 사용하면 보유하고 있는 GPU의 활용도를 높여 더 효율적으로 활용할 수 있습니다. 만약 앞에서 예를 든 사례에서 MIG 모드를 적용한 A100을 사용한다면, 다양한 크기의 AI 또는 HPC 워크로드를 혼합해 실행할 수 있으므로, 1개의 GPU를 여러 팀에서 같이 사용할 수 있도록 구성할 수 있게 되는 것입니다. (0.1개의 아쉬움을 이렇게 해결할 수 있다니!)
물론, H100에서도 MIG가 가능하며, Hopper 아키텍쳐를 기반으로 하고 있기에 가상화된 환경까지 더해져 안전성 등의 부분에서 좀 더 향상된 MIG를 활용할 수 있습니다. 😊
[ GPU를 나눠 쓸 수 있다는 거죠? MIG의 장점은 그것뿐인가요? ]

MIG 모드는 GPU를 ‘독립된’ 인스턴스로 분할한다고 말씀드렸는데요. 이 독립성은 오류 등의 문제 상황에서도 그대로 적용됩니다. MIG는 GPU 인스턴스를 분할해서 서로 독립적으로 기능할 수 있게 차단하기 때문에, 다른 인스턴스에 영향을 주지 않습니다. 그러니까, 같은 GPU를 사용하고 있던 옆 부서의 AI 모델에서 결함이나 오류가 발생하더라도, 같은 GPU를 사용하고 있는 내 부서의 AI 모델은 영향을 받지 않는 것입니다. MIG 덕분에 외부 요인에 영향을 받지 않고 서비스 품질을 유지하며 모델 개발을 할 수 있지요.👏
또한 MIG로 독립된 인스턴스들이 각각 작업을 할 수 있는 환경이 되므로, 여러 워크로드를 동시에 실행하는 것도 가능합니다. 모델 학습, 고성능 컴퓨팅, 모델 추론을 하나의 GPU에서 동시에 할 수 있습니다. 병렬 실행이 가능하다는 점은 효율성의 측면에서 AI뿐만 아니라 어떤 개발에서든 참 매력적인 포인트잖아요. 만약 MIG를 적용할 수 없는데 병렬 실행을 해야 한다면, 단순 계산으로 각각의 워크로드에 GPU 1장씩, 총 3장을 준비해야 했을 거예요. 만약 GPU가 단 하나뿐이라면, 우선순위를 정해 순차적으로 활용해야 했겠지요. (병렬 포기🥲)
MIG로 생성한 인스턴스의 구성을 바꿀 수도 있습니다. GPU 자원을 활용하는 양상이 낮과 밤 모두 같을 수는 없으니까요. 모든 사람이 출근해 있는 낮에는 7개까지 인스턴스를 사용하고, 사람들이 퇴근하고 없는 밤에는 딥러닝과 같이 대용량, 장시간 학습이 필요한 모델을 위해 1개 내지 2개의 인스턴스를 사용할 수 있어요. GPU를 아주 효율적으로, 야무지게 쓰는 방법이지요.🤓
[ GPU를 나누어 쓰는 건 꼭 7개까지만 가능한 건가요? ]
MIG에 대해 궁금하시거나 고민이 더해지신 분들도 있으실 것 같습니다. 7개의 독립된 인스턴스로는 커버할 수 없는 상황에 부닥친 분들도 있으실 테니까요. 어떤 기업에서 여러 부서가 동시에 AI 모델 개발에 착수한다면, 그 수가 7개 이상일 수도 있지 않을까요? 또한 각 모델이 필요로 하는 GPU의 공간도 다를 것입니다. GPU를 꼭 7개까지만 나눠 쓸 수 있는 것일까요?🤔
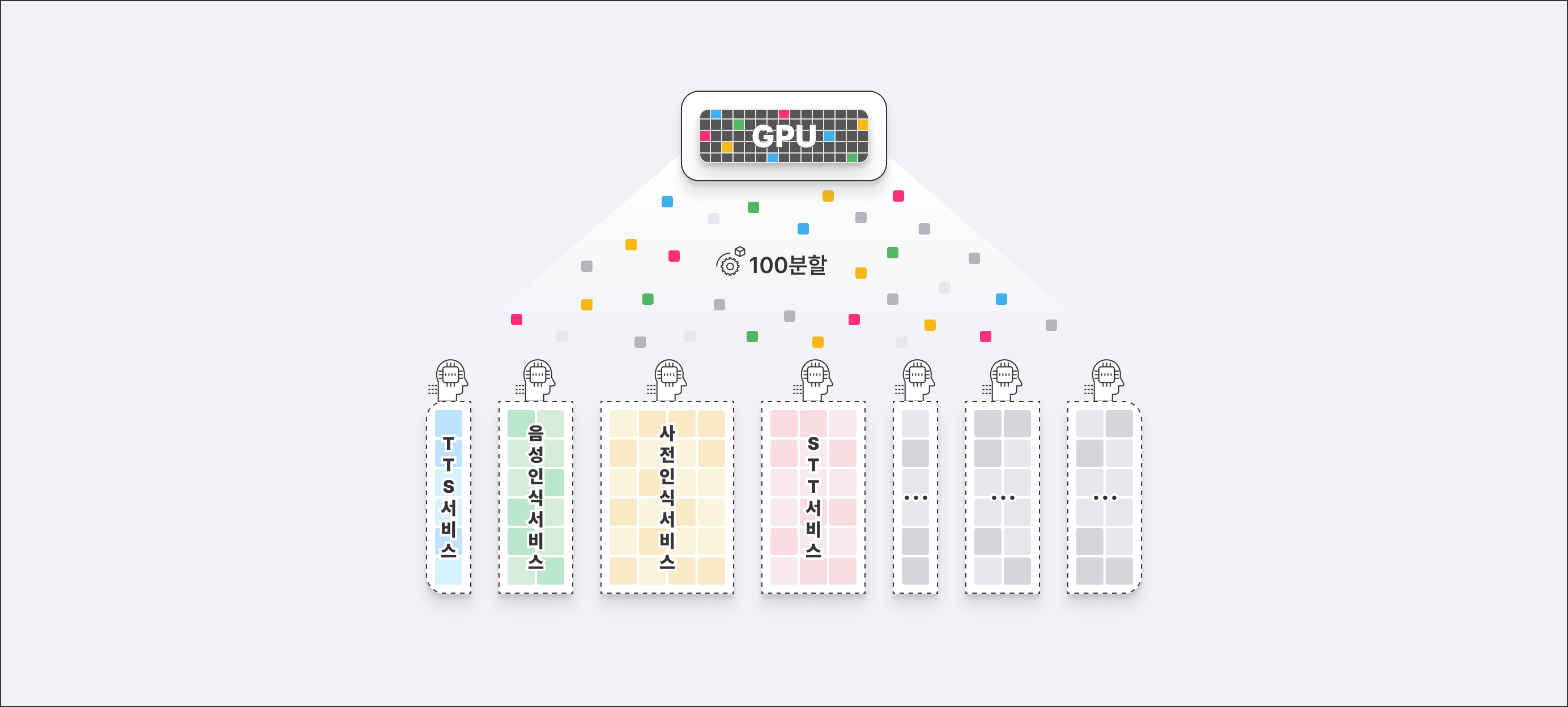
보유하고 있는 자원을 필요에 맞게 나눠 쓰는 방식이 꼭 MIG만 있는 것은 아닙니다. 예를 들어, TEN에서 제공하고 있는 AI Pub이 있습니다. AI Pub은 GPU를 포함한 자원을 각 워크로드에서 필요로 하는 양만큼 할당하는 방식을 제안하고 있는데요. TEN의 Kubernetes 확장 컨테이너 플랫폼 Coaster의 기능을 기반으로 해서 100분할까지 할 수 있습니다. GPU를 100개의 ‘블록’으로 쪼개서, 각각의 사용자들에게 할당할 수 있다는 의미로 ‘블록 타입’이라는 용어를 사용합니다.🤓
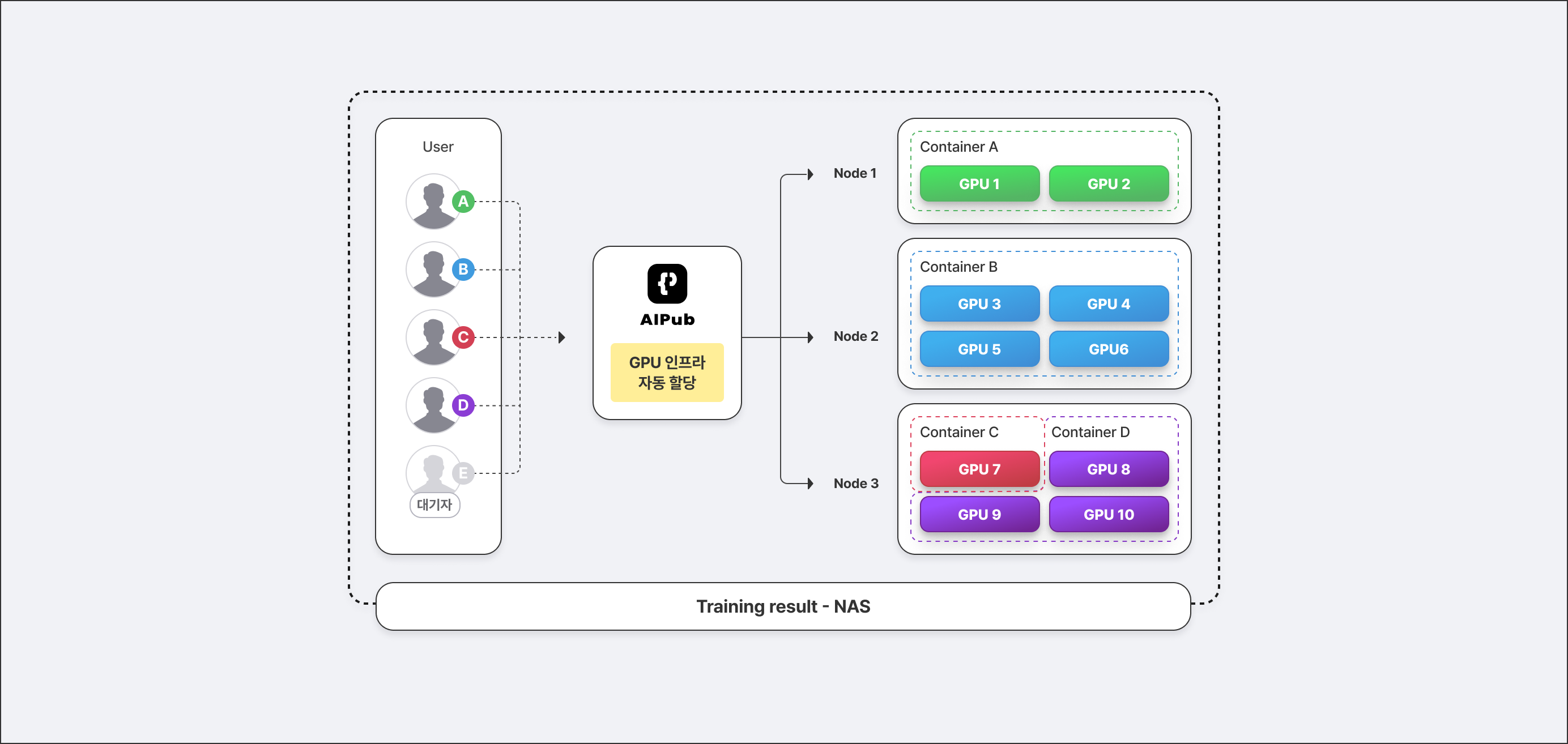
보유한 자원의 블록 타입은 그룹 단위로 할당한 후, 그 그룹에 할당된 자원 안에서 개인이 필요한 만큼 자원을 더 할당받는 방식으로 관리할 수도 있습니다. 보통 MIG 모드를 활용할 때는 최대 7개로 생성한 독립된 인스턴스를 7개 팀에 할당한다고 해도, 그 팀 안에서 1개의 독립된 인스턴스를 개인 단위로 어떻게 나눌지가 애매할 수 있는데요. AI Pub에서는 ‘리소스 그룹’이라는 개념을 도입해서, 그룹과 개인 단위의 자원 관리가 모두 가능합니다.👏
모델의 개발, 학습, 그리고 운영을 위한 워크스페이스를 만들고, 그 워크스페이스에 필요한 만큼의 리소스를 입력하여 신청하면, 리소스 관리자가 승인 및 관리할 수 있는 방식이에요. 할당받은 자원이 얼마나 가동되고 있는지는 사용 중인 사람과 관리자 모두 실시간으로 모니터링할 수 있습니다.
리소스를 많이 보유하고 있어 효율적인 관리가 필요하다거나, 적은 자원을 효율적으로 사용하기 위해 유용한 방식입니다. 이 모든 관리는 Web UI로 제공되기 때문에, 사용하시기에 불편함이 적다는 것도 큰 장점이에요.😊
요즘은 경쟁적으로 LLM, LMM 등 거대 규모의 AI 모델을 개발하고 있는데요. 가지고 있는 자원을 효율적으로 쓸 수 있다는 것은 경쟁 과정에서부터 우위를 점할 수 있는 부분입니다. GPU나 밴드 등의 인프라 자원을 구하는 것도, 유지 관리하는 것도 모두 큰 비용이 드는 일이기 때문이지요. ‘자원 효율’이란 주제는 지금도 그렇지만, 앞으로도 AI 시장에서 매우 중요한 화두가 될 것이기에, 다양한 방법을 고민해 봐야 할 것 같네요. 그럼, 에디터 SA는 쉽고 재미있는 AI 이야기를 준비해 다음에 다시 찾아오겠습니다!
'Tech & Product > AI, 더 쉽게' 카테고리의 다른 글
| AI에게 유전병이 있다? (4) | 2023.11.20 |
|---|---|
| 주피터 노트북이요? 어느 회사 노트북인가요? (1) | 2023.11.03 |
| AI 개발, 운영에 있어 빠질 수 없는 '도커(Docker)'에 대해 알아보기! (0) | 2023.10.06 |
| 인공지능 시장에서 제일 귀하신 몸, GPU를 알아보자 (1) | 2023.09.26 |
| 빙글빙글 돕니다, MLOps Lifecycle (1) | 2023.09.13 |



