

유럽에서 가장 긴 역사와 전통을 지닌 가문이 있습니다. 바로 오스트리아의 합스부르크 왕가입니다. 세계사에 관심이 있으시다면 한 번쯤 들어본 적 있으실 텐데요. 합스부르크 왕가가 어떤 기념비적인, 역사적인 사건과 성과 속에 있었는지 아시는 분은 아마 많지 않으실 것 같아요. 스위스 알프스 지역에 있던 작은 가문에 불과했던 합스부르크 가문은, 루돌프 백작이 신성 로마 독일의 왕이 되면서 ‘왕가’의 반열에 들어서게 되었습니다. 1차 세계대전에서 패배하면서 사라졌지만, 1900년대까지 약 650년간 명맥을 유지했어요.
그런데, 왜 갑자기 합스부르크 왕가 이야기냐고요? 이 ‘합스부르크’가 AI와 관련이 있기 때문입니다. 1900년대 초에 사라진 왕족 가문에 갑자기 AI라니, 너무 뜬구름 잡는 이야기 같으시겠지만요. 왜 AI에 갑자기 왕족의 이야기가 등장하게 되었는지, 오늘 ‘AI., 더 쉽게’에서 알려드리겠습니다.
[ 합스부르크 왕가가 어땠기에, AI랑 엮이나요? ]
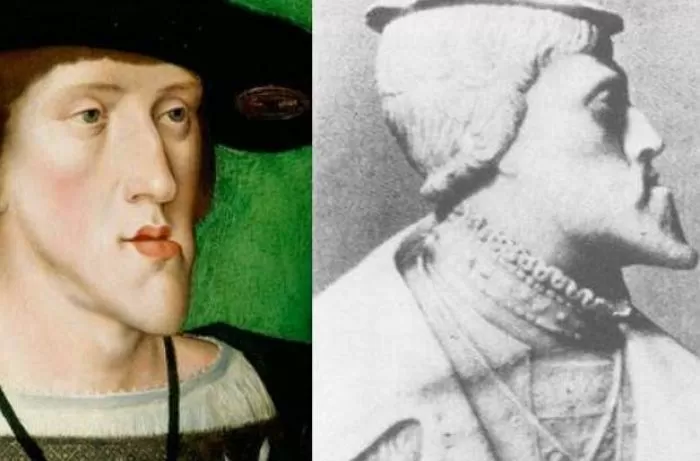
합스부르크 왕가는 ‘오랜 역사’ 외에도 인상적인(!) 타이틀을 더 갖고 있습니다. 그중 하나가 바로 ‘근친혼’입니다. 합스부르크는 일명 ‘결혼 정책’이라고 불리는 동맹 방식으로 평화를 유지했는데요. 처음에는 효과가 꽤 있기도 했고, 재산을 상속하는 과정에서 스페인을 계승한 시점부터 근친혼이 극단적인 방향으로 전개되었다고 합니다.
합스부르크 왕가가 쇠퇴하는 데에 근친혼이 영향을 주기도 했습니다. 근친혼으로 인해서 유전병으로 인한 영아 사망이라던가, 무능한 왕의 즉위 같은 일들이 생기게 된 것이죠. 대 잇기에 문제가 생기고, 합리적인 의사결정을 할 수 없는 왕으로 인해 국가 안위가 흔들리기도 합니다. 합스부르크 왕가를 검색해 보시면 여러 초상화를 보실 수 있는데요. 주걱턱이 극대화된 생김새, 눈빛이 불안해 보이는 등 유전병의 징후를 확인하실 수 있어요. 실제로 카를로스 2세의 경우 말을 하기도 힘들 정도의 불편을 겪었다고 합니다.
이런 합스부르크 왕가의 특징이 AI에도 나타날 수 있습니다. AI가 결혼을 하냐고요? AI에 형제가 있냐고요? ‘AI’는 사람의 핏줄, DNA 대신 ‘데이터’를 가집니다. 데이터 학습을 거듭하며 완전해지는 ‘AI’에, 만약 잘못된 데이터 혹은 같은 데이터를 반복 학습하게 되면 어떤 결과가 나타날까요? 합스부르크 왕가처럼 ‘유전병’이 나타나는 걸까요?
[ AI가 학습할 데이터를 AI가 만든다?! ]

인터넷이 정보의 바다라고는 하지만, 그 바다에도 한계는 있습니다. 실제로 ChatGPT는 웹에서 찾을 수 있는 정보 대부분을 학습했다고 하죠. 앞으로 출시되는 AI 모델 중 LLM, LMM 등 많은 데이터를 학습해야 하는 모델들은, 현존하는 웹상의 데이터 대부분을 학습한 상태로 출시될 거예요.
하지만, 정말 모든 데이터라고 말할 수 있을까요? 웹에 있는 정보들은 우리가 보기에도 고품질 데이터라 할 것이 많지 않아 검색을 거듭해야 하지요. 의료정보나 개인정보처럼 접근이 제한되는 규제 대상의 정보들도 있고요. 웹을 이용하는 인종이나 성별 등의 사회적 조건들을 고려하면, 정보들이 특정 계급 및 계층에 편중되어 있기도 할 거예요.
예를 들면, 우리는 고려시대 복식에 대한 이미지를 쉽게 찾을 수 있습니다. 하지만 중국 어느 소수민족의 1500년대 복식 이미지를 찾기는 어렵지요. 만약 있다 해도 그 수는 엄청나게 적을 것이라 그 데이터가 진짜인지, 대표성이 있는지 확인하기도 어려울 거예요.

그래서 사람들은 AI에 ‘합성 데이터’를 학습시키기 시작했습니다. ‘합성 데이터’는 원본 데이터의 통계적 특성과 구조를 이용해 만들어 낸 인공 데이터입니다. 이 합성 데이터도 AI를 활용해 만들어 내는데요. AI가 만든 정보를 다른 AI 모델이 학습하게 됩니다.
실제로 금융, 유통업계에서는 이 합성 데이터를 활용해서 고객 행동 예측, 사기 예방, 시장 분석 등을 시뮬레이션하는데요. 합성 데이터는 현실의 데이터와 유사한 구조와 속성이 있어서 활용도가 높다고 해요. 개인정보와 민감정보를 담고 있지도 않을 테니, 해당 데이터를 생산하거나, 그 데이터에 노출된 사람들에게 동의를 구하지 않아도 되겠지요.
물론 이런 고품질 데이터를 직접 만들기 위해서는 큰 비용이 들겠지만, AI는 100분의 1에 불과한 비용으로 합성 데이터를 만들어 냅니다. 이 데이터를 AI가 학습하는 추세가, 최근 AI 업계에 나타나게 된 것이죠.
그런데, 앞에서 이야기한 ‘합스부르크 왕가’와 어딘가 유사하다고 느끼지 않으셨나요? 맞습니다. AI는 AI에게 배우기 시작했어요. 물론 이게 나쁜 것은 아닙니다. AI가 만들어 낸 ‘합성 데이터’에 오류가 없다면 말이지요.
[ AI의 유전병, 합스부르크 부메랑 ]

2023년 5월, 옥스퍼드대학에서는 이 ‘합성 데이터’의 오류를 경계하는 ‘반복의 저주’라는 논문을 발표했는데요. “허위나 조작이 포함된 결과물로 인공지능 모델을 학습시키면 시간이 지나면서 기술이 손상되고 저하되어 ‘돌이킬 수 없는 결함’이 발생하고 모델 붕괴로 이어진다”고 경고했습니다. 잘못된 데이터를 학습하고 난 후, AI 모델이 이를 기반으로 다른 학습을 거듭하면서, 그 ‘결함’이 급속도로 퍼져나가기 때문이에요.
이렇게 ‘AI’가 만든 합성 데이터로 학습한 ‘AI’가 손상될 수 있는, 혹은 손상되는 경우를 일컬어, ‘합스부르크 인공지능’이라고 부릅니다. 다른 생성 인공지능의 결과물을 지나치게 많이 학습한 시스템이 과장되고 기괴한 특징을 가진 근친교배 돌연변이가 되는 현상을 ‘합스부르크 왕가’의 유전병에 비유한 거죠.
실제 데이터가 충분하지 않다거나, 합성 데이터를 만드는 AI를 사용하는 게 비용이 더 저렴하다거나 하는 등 여러 가지 이유로 많은 AI 모델들이 합성 데이터를 사용하고 있습니다. 만약 여기에서 합성 데이터에 작은 오류가 생긴다면, 이 오류를 바탕으로 학습한 AI의 정확도는 떨어지게 되겠지요. 이 문제는 하나의 AI 모델에서 끝나지 않습니다. 같은 데이터를 다른 AI 모델이 학습하게 될 수도 있어요.
또한 잘못된 데이터를 학습해서 만든 잘못된 결과, 즉 AI의 ‘환각’을 또 다른 AI 모델이 웹에서 수집해서 학습하게 될 수 있습니다. 이렇게 잘못된 AI 데이터에서 시작된 AI들이 무한한 되먹임 효과에 의해서 점차 품질 저하를 겪게 되면, 이걸 어떻게 수습할 수 있을까요…?

안타깝게도 ‘합스부르크 부메랑’에 대한 해결책은 아직 정확하게 나와 있지 않습니다. 정확한 데이터를 더 학습시켜 정확도를 높이는 방식을 계속해서 시도하고 있으나, 어쨌든 완전한 문제 해결은 되지 않는다는 점에서 여전히 우려의 목소리가 나오고 있어요.
OpenAI에서 ‘환각’ 문제를 해결하는 것에 중점을 둔 GPT-5를 개발 중이라고 하니, 새로운 대안이 또 나오지 않을까 하는 기대를 해봅니다. 많은 AI 개발자들이 이 문제를 해결하기 위해 백방으로 노력하고 있으니, ‘합스부르크 왕가’가 사라진 것과는 다른 결과가 AI에게 나타나지 않을까요? 시간이 조금 더 필요하겠다는 생각이 듭니다. 지금까지 에디터 SA였습니다!
'Tech & Product > AI, 더 쉽게' 카테고리의 다른 글
| 머신러닝, 딥러닝을 인간의 뇌 이미지로 표현하는 이유! 인공신경망과 노드 (4) | 2023.12.26 |
|---|---|
| GPU로 AI 개발하면 안다 안다 다 안다! CUDA를 소개합니다! (2) | 2023.12.18 |
| 주피터 노트북이요? 어느 회사 노트북인가요? (1) | 2023.11.03 |
| GPU를 이렇게 쓴다고? MIG 모드와 효율적인 분할 사용! (2) | 2023.10.19 |
| AI 개발, 운영에 있어 빠질 수 없는 '도커(Docker)'에 대해 알아보기! (0) | 2023.10.06 |



