

안녕하세요. TEN에서 RA:X 서비스를 담당하는 개발자 정수현입니다.
RA:X는 TEN의 AI 인프라 구축 노하우를 더한 테스트 기반의 AI 인프라 구축 컨설팅 서비스입니다. 서비스명은 간단히 '랙스' 라고 불러주시면 됩니다. 보통 AI 인프라를 구축하는 과정에서 예산을 우선하다 보니, 실제 활용도, 성능에 대한 부분을 미처 고려하지 못하고 하드웨어를 구입하는 경우가 생깁니다. TEN은 AI 인프라를 더 효율적으로 구축할 방법이 필요하다고 생각했고, 인프라 전체의 가치를 볼 수 있도록 하는 가이드라인을 만들게 됐습니다. 그 결과 RA:X는 사용자가 활용할 AI 모델, 데이터 샘플을 참고해 테스트를 거쳐, 성능 측정치에 맞춘 인프라를 구축할 수 있도록 하고 하드웨어 구입에 대한 가이드라인을 제시합니다.
저는 그 과정에서 다양한 모델과 데이터 샘플을 토대로, TEN이 보유한 Reference Architecture에서 성능을 측정하는 테스트를 중점적으로 수행합니다. 그래서 AI 피드의 [AI, 더 깊게]의 첫 주제로, AI 인프라에 대한, 아직 많은 분에게 생소할 수 있는 기술을 다뤄 보면 어떨지 생각했습니다.
제가 소개할 내용은 인피니밴드(Infiniband)라는 네트워크 기술입니다. 저를 포함한 많은 딥러닝 관련 개발자들, 특히 하드웨어보다 소프트웨어와 더 밀접한 개발자에게는 아주 생소한 기술일 것 같습니다.
[ 인피니밴드(Infiniband)란 ]
인피니밴드(Infiniband)는 이름에서 알 수 있듯이 무한대(Infinite)의 대역폭을 제공한다는 개념에서 유래되었습니다. ‘무한대’의 대역폭이 필요할 수밖에 없는, 고성능 컴퓨팅과 기업용 데이터 센터에서 주로 볼 수 있습니다. 스위치 방식이며, 컴퓨팅 노드와 스토리지 장비와 같은 고성능 I/O 장비 간의 연결에 사용됩니다.
대부분의 컴퓨터 장치는 버스 기반의 I/O 아키텍처를 채택하고 있는데, 이 버스 인터페이스의 IO 병목 한계를 해결하기 위해 개발된 것이 바로 ‘인피니밴드’입니다.
[ 인피니밴드(Infiniband), 왜 주목 받는가 : 세 가지 특징 ]
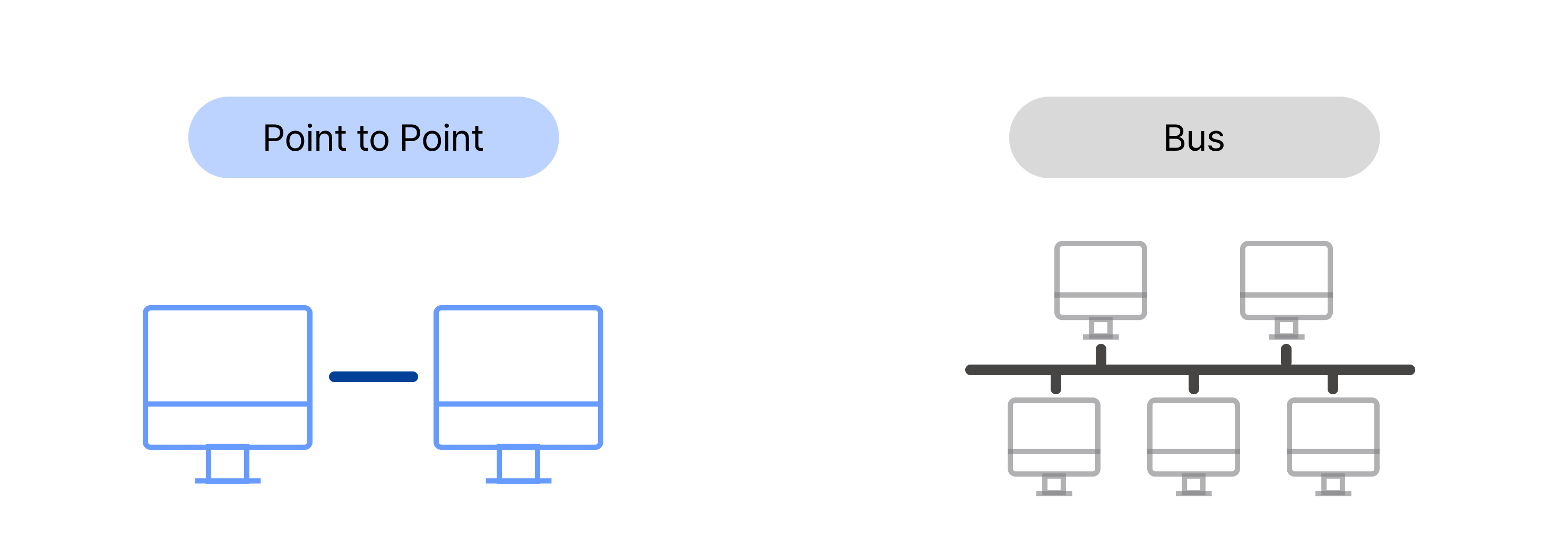
인피니밴드의 특징은 연결 방식, 스위치, 프로토콜에서 각각 한 가지씩 추려 크게 세 가지로 정리해 볼 수 있습니다.
첫째, 전통적인 버스 기반 방식 대신, 포인트-투-포인트 연결 방식을 사용합니다.
이렇게 연결하게 되면, 연결된 장치 간에는 다른 트래픽의 간섭이 없게 됩니다. 공유 구조인 버스 기반 방식에서 겪었던 트래픽 문제가 사라진다는 거죠. 또한, 오류 발생 시 해당 연결만 영향을 받아 네트워크의 다른 부분에는 문제가 발생하지 않습니다. 호스트 채널 어댑터(HCA)로 각각의 컴포넌트를 연계하기 때문에 장비 하나가 다운되더라도 다른 장비에는 영향을 미치지 않는 리던던시(Redundancy, 여유도)가 보장되는 것입니다.
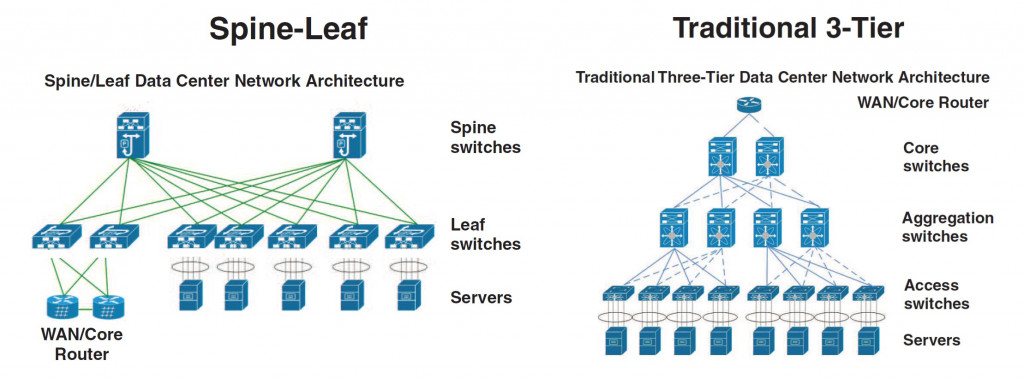
두 번째 특징으로 소개할 점은 ‘토폴로지’에 관한 것입니다.
인피니밴드에서는 계층적 스위치 방식의 토폴로지가 아니라 스위치 패브릭 방식의 토폴로지를 사용합니다. 위에 첨부된 이미지를 기준으로 하면, 좌측이 ‘스위치 패브릭’ 방식의 토폴로지이고, 우측이 ‘계층적 스위치’ 방식의 토폴로지입니다. 다수의 개발자분에게는 우측의 토폴로지가 익숙하셨을 것입니다.
인피니밴드는 좌측의 스위치 패브릭 방식을 채택해서, 높은 확장성과 유연성을 제공하도록 했습니다. 계층 구조와 달리 여러 경로를 통해 데이터를 전송할 수 있어 높은 가용성과 장애 허용성을 가집니다.
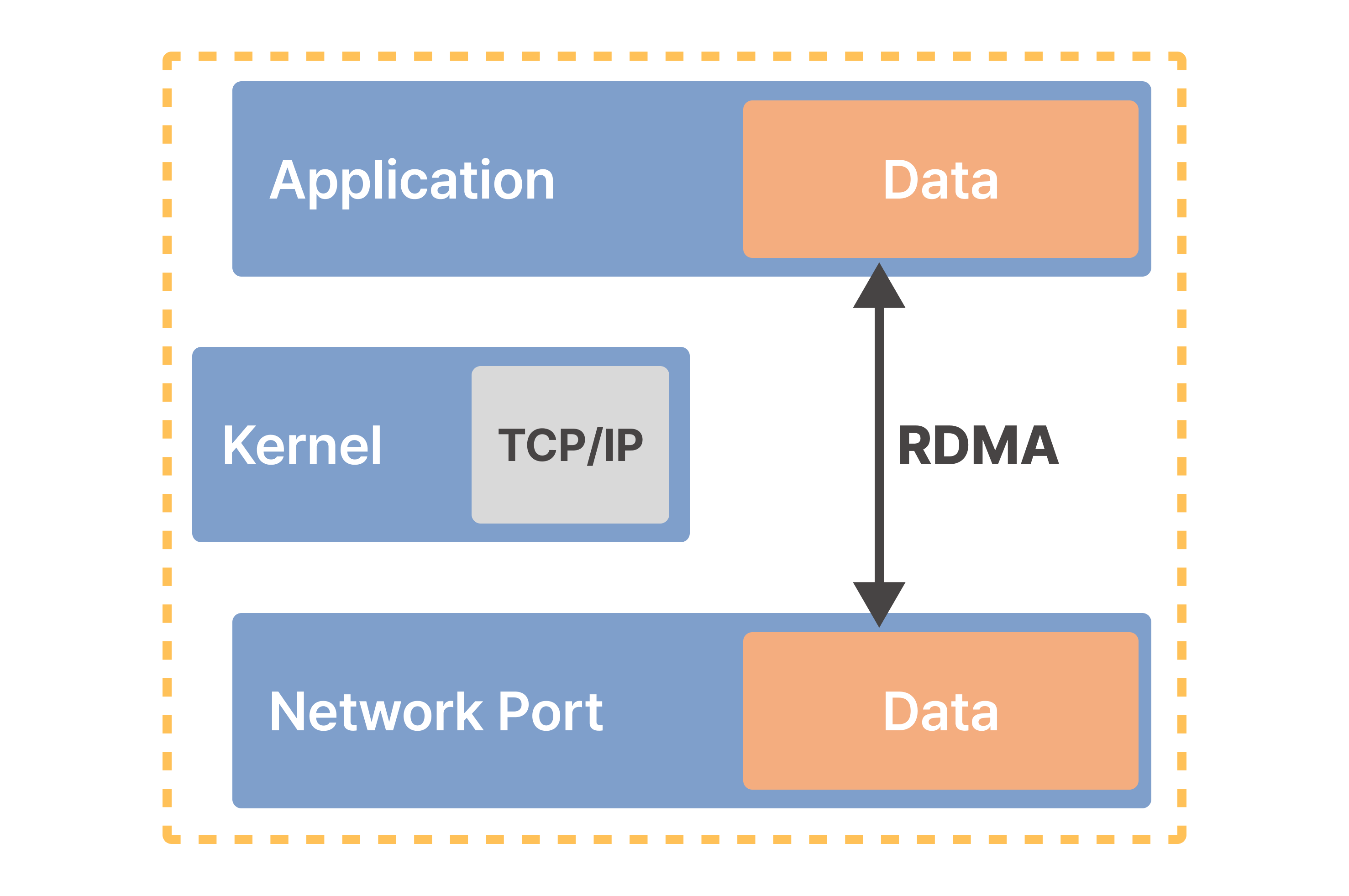
인피니밴드의 세 번째 특징으로 꼽을 수 있는 것은 바로 ‘RDMA’입니다.
‘RDMA’ (Remote Direct Memory Access)는 프로토콜이며, 인피니밴드에서는 RDMA를 사용해 애플리케이션과 네트워크 포트 사이에 직접적으로 데이터를 송수신할 수 있습니다. 이는 커널의 개입이 없어지는 것인데요. 컴퓨팅 리소스 사용량을 줄이고 많은 TCP 버퍼링 계층을 거치지 않아 데이터 전송 속도를 높이는 데 효과가 있습니다.
최근에 급부상하고 있는 Generative AI의 기반이 되는 LLM(Large Language Model)은 모델의 파라미터 수가 매우 많습니다. 이렇게 큰 모델을 학습시키려면 단일 GPU로는 당연히 커버하기 어렵습니다. 그래서 학습 시 멀티 GPU 및 멀티 노드 사용이 거의 필수가 되었습니다.
거대 모델을 학습시킬 때는 여러 프로세스가 생성되는데, 각 프로세스는 하나의 GPU를 할당받고 학습을 진행합니다. 모든 프로세스는 각자가 학습하고 있는 모델의 기울기를 스텝마다 동기화합니다. 그 때문에 엄청난 양의 데이터를 주고받아야 하죠. 그래서 주로 HPC를 운용하는 데이터 센터, 특히 거대 딥러닝 모델을 학습하는 기업에서 인피니밴드를 더 효과적으로 사용하고 있습니다.

비단 인피니밴드뿐만 아니라 이더넷으로 대용량 데이터를 더 효율적으로 송수신하기 위한 기술들이 많이 개발되고 있습니다. 대표적으로, 앞서 인피니밴드의 특징 중 하나로 설명한 RDMA를 이더넷 기반으로 사용할 수 있는 기술, RoCE(RDMA over Converged Ethernet)를 예로 들 수 있습니다.
따라서 무조건 인피니밴드가 좋다고 보기는 어렵습니다. 대체로 하드웨어의 사양이란 사용자의 사용 목적, 상황, 조건 등에 따라, 적절할 수도, 모자랄 수도 있기 때문입니다. 만약 RA:X에서 AI 인프라에 대한 컨설팅을 진행하면서, 인피니밴드와 이더넷을 각각 세팅해 두고 같은 태스크를 수행했을 때 차이가 미미한 것으로 성능 측정치가 확인된다면, 굳이 값비싼 인피니밴드 장비(스위치, 케이블 등)를 도입하여 세팅하도록 권장하지는 않습니다.
이러한 고급 네트워킹 기술을 이해하고 활용하는 것은, 우리가 더욱 진보된 AI 시스템을 구축하는 데 있어 중요한 열쇠가 될 것입니다. 이 포스팅을 통해 저처럼 하드웨어 인프라에 관심이 없으셨던 개발자분들도 시야가 넓어지는 계기가 되었으면 좋겠습니다.
'Tech & Product > AI, 더 깊게' 카테고리의 다른 글
| RA:X 서비스 개발자의 인사이트: 혼합 정밀도와 GPU 성능 비교 (0) | 2024.04.01 |
|---|---|
| AI Pub 프론트엔드 개발자가 소개하는: 웹 테스트 자동화 프레임워크 (0) | 2024.02.23 |
| 주식회사 텐, Coaster Auth 오픈소스 공개 (0) | 2022.05.20 |
| JSON Patch (0) | 2022.04.01 |
| Docker의 등장 배경과 구조 (1) | 2022.03.15 |



